Longguang Zhong
About Me
Hello, I’m Longguang Zhong, a Member of Technical Staff at Moonshot AI, working on large language models. I received my M.S. in Computer Technology from Sun Yat-sen University, advised by Prof. Xiaojun Quan, and my B.E. in Software Engineering from Xidian University.
Research Interests
My research focuses on large language models, with a current emphasis on agents and reinforcement learning.
News
[February 2026] 🔥🔥 We release Kimi K2.5, an open-source visual agentic intelligence model. Check out the tech report here.
[October 2025] 🔥🔥 We release Kimi Linear, an expressive and efficient attention architecture. Check out the tech report here.
[July 2025] 🔥🔥 We release Kimi K2, an open agentic intelligence model. Check out the tech report here.
[August 2025] 🔥🔥 ThinkSwitcher, our work on adaptive thinking strategies for language reasoning models, is accepted to EMNLP 2025 Findings! Check out the paper here.
[August 2025] 🔥🔥 FuseChat, our work on knowledge fusion of chat models, is accepted to EMNLP 2025 Main! Check out the paper here and the code on GitHub.
[May 2025] 🔥 BlockPruner, a fine-grained block pruning framework for large language models, is accepted to ACL 2025 Findings! Check out the paper here and the code on GitHub.
[April 2025] 🔥 We release FuseRL, a dense preference optimization framework for heterogeneous model fusion. Check out the tech report here.
[Jan 2025] 🔥 We release FuseO1-Preview, an advanced fusion model that enhances System-II reasoning by integrating multiple O1-like models using SCE merging, excelling in mathematics, coding, and science.
[Dec 2024] 🔥 We release FuseChat-3.0 and Blog Post. FuseChat-3.0 contains a series of models crafted to enhance performance by integrating the strengths of multiple source LLMs into more compact target LLMs.
[Aug 2024] 🔥 We update the FuseChat tech report and release FuseChat-7B-v2.0, which is the fusion of six prominent chat LLMs with diverse architectures and scales. FuseChat-7B-v2.0 achieves an average performance of 7.38 on MT-Bench (GPT-4-0125-Preview as judge LLM), which is comparable to Mixtral-8x7B-Instruct and approaches GPT-3.5-Turbo-1106.
Publications
-
 Tech Report
Tech Report
-
 Tech Report
arXiv preprint arXiv:2510.26692, 2025.PDF Tech Report
Tech Report
arXiv preprint arXiv:2510.26692, 2025.PDF Tech Report -
 Tech Report
Tech Report
-
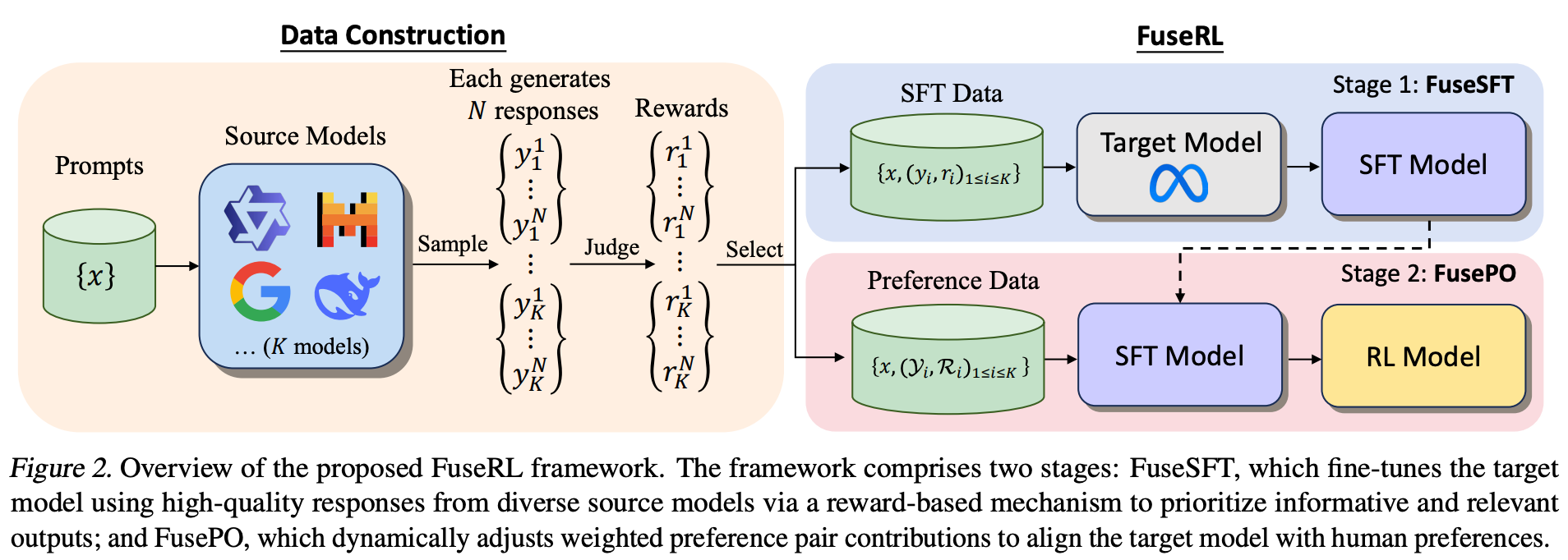 Tech Report
arXiv preprint arXiv:2504.06562, 2025.PDF Tech Report
Tech Report
arXiv preprint arXiv:2504.06562, 2025.PDF Tech Report -
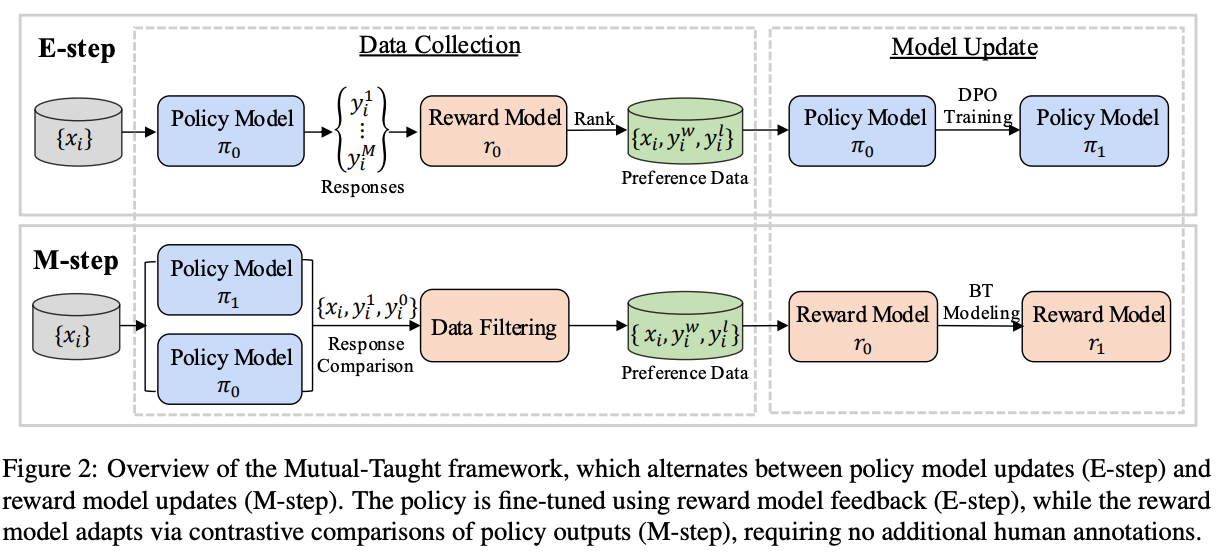 ACL
The 63rd Annual Meeting of the Association for Computational Linguistics (ACL), 2025.PDF Main
ACL
The 63rd Annual Meeting of the Association for Computational Linguistics (ACL), 2025.PDF Main -
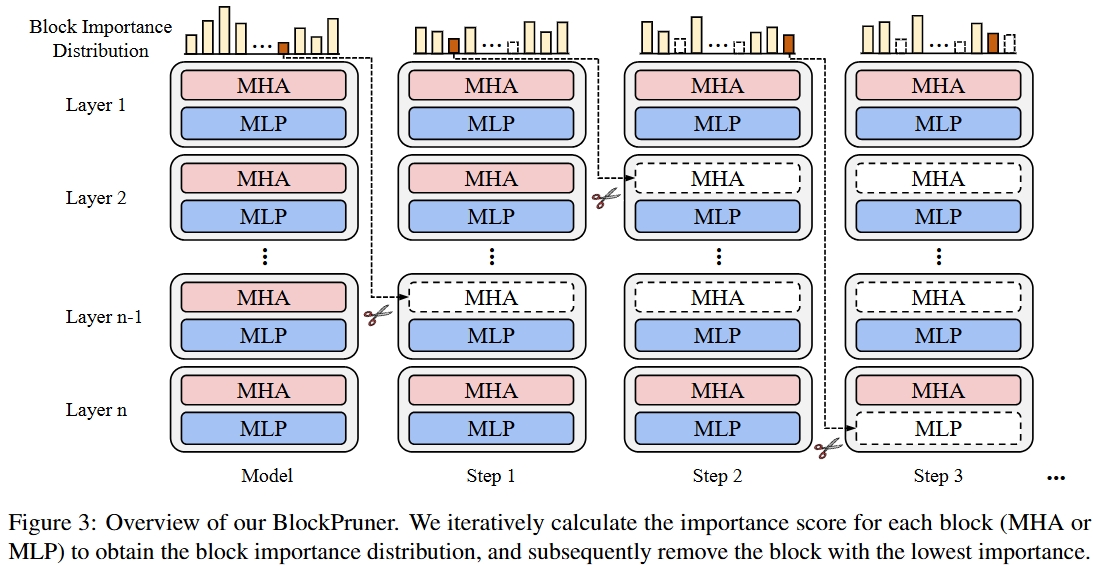 ACL
The 63rd Annual Meeting of the Association for Computational Linguistics (ACL), 2025.
ACL
The 63rd Annual Meeting of the Association for Computational Linguistics (ACL), 2025. -
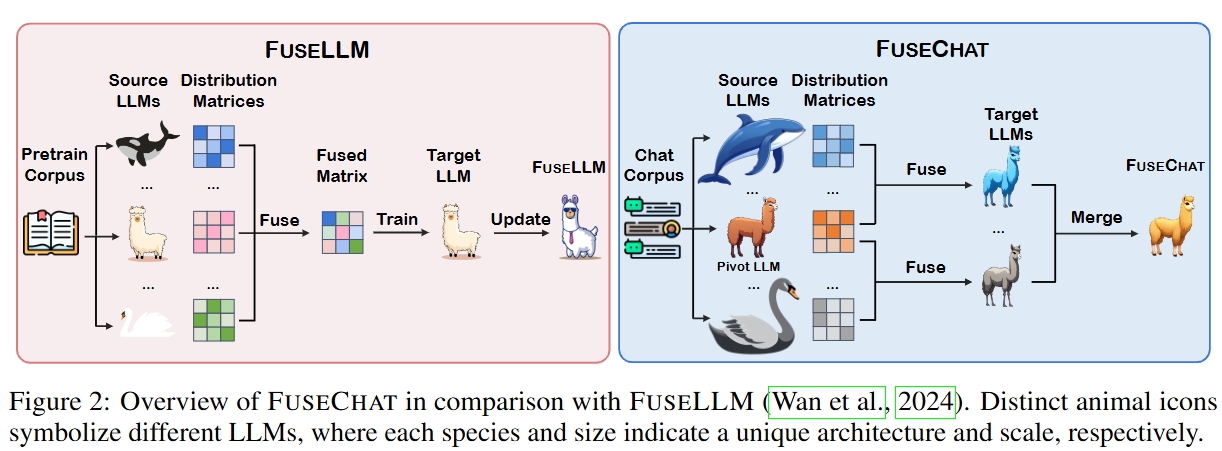 EMNLP
The 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2025.
EMNLP
The 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2025. -
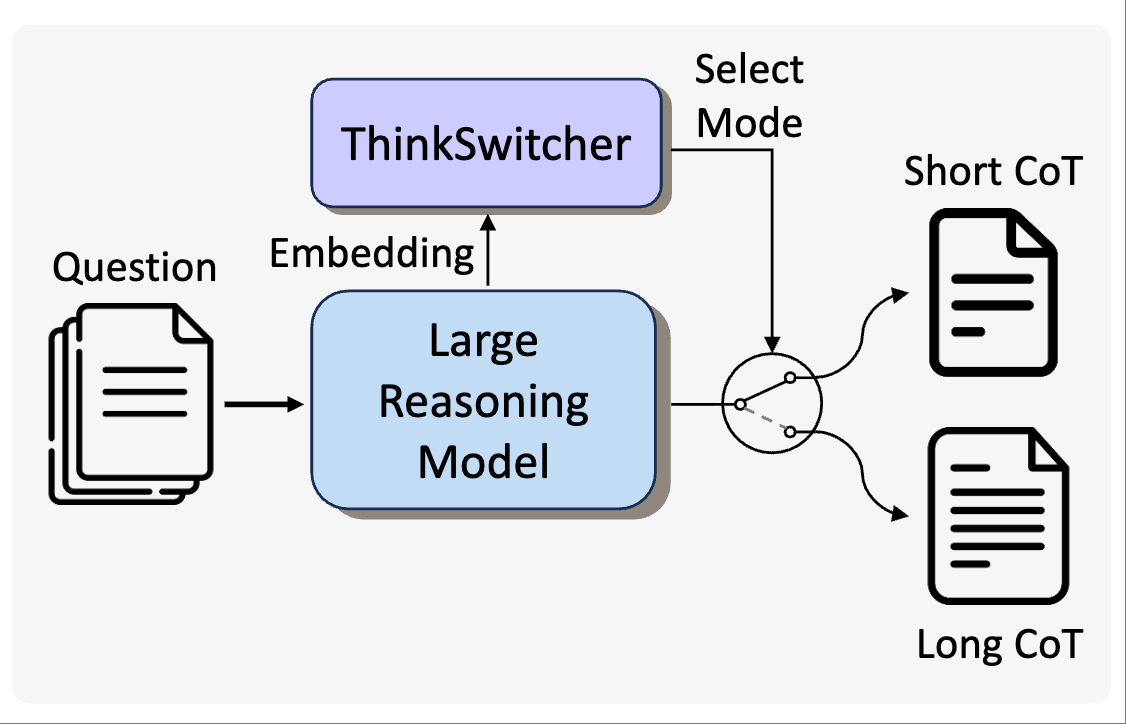 EMNLP
The 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2025.PDF Findings
EMNLP
The 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2025.PDF Findings -
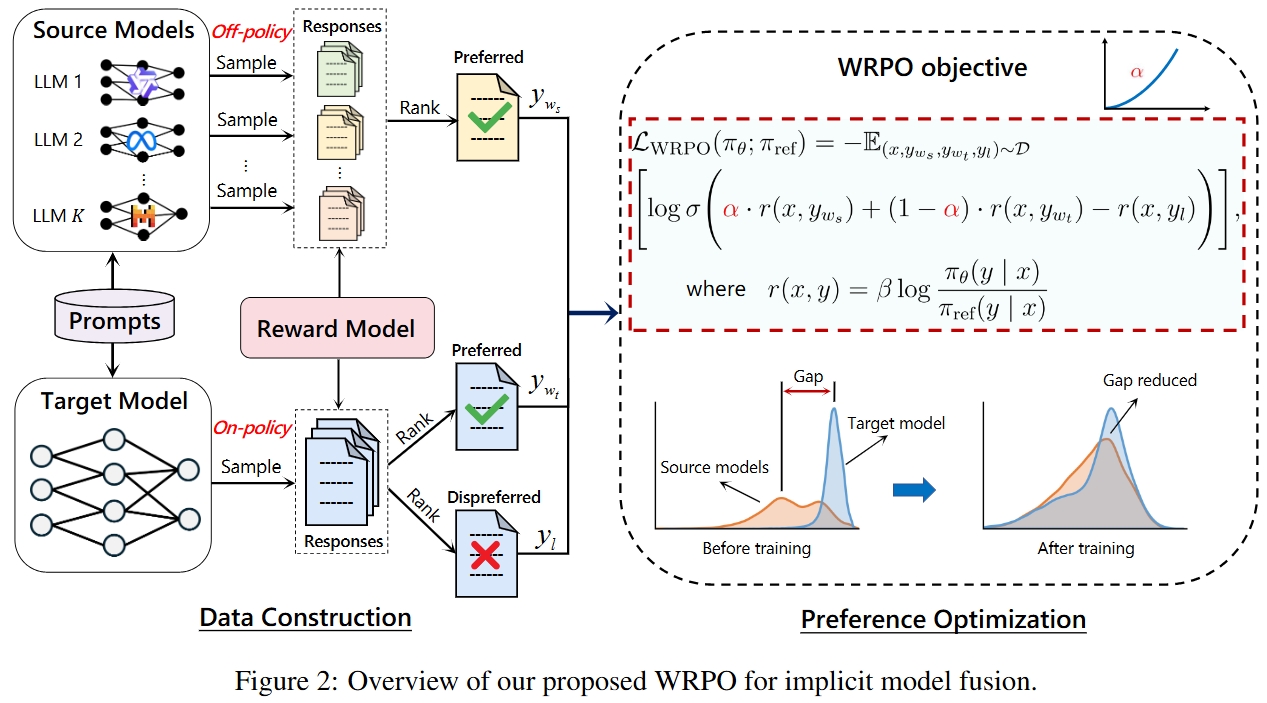 ICLR
The Thirteenth International Conference on Learning Representations (ICLR), 2025.
ICLR
The Thirteenth International Conference on Learning Representations (ICLR), 2025. -
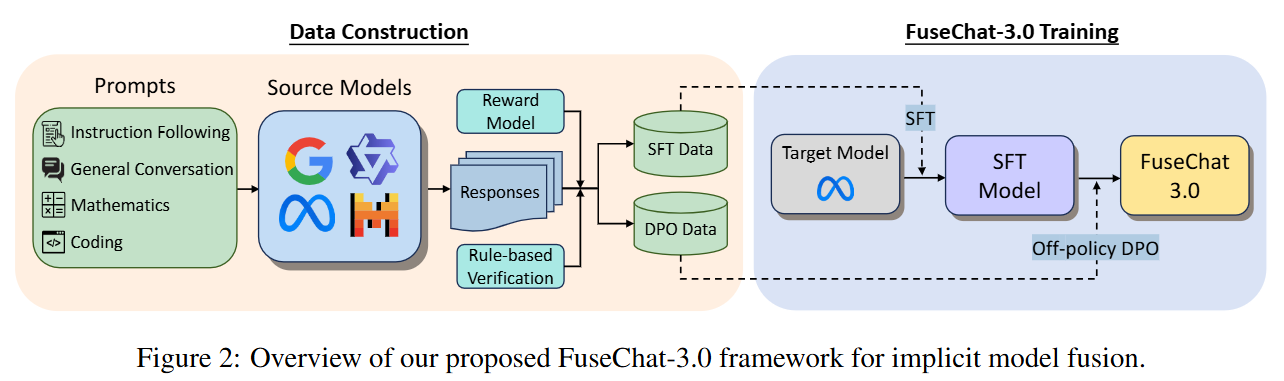 ICLR Workshop
ICLR 2025 First Workshop on Open Science for Foundation Models (ICLR WorkShop), 2025.
ICLR Workshop
ICLR 2025 First Workshop on Open Science for Foundation Models (ICLR WorkShop), 2025.